
En esta sesión explicaré algunos aspectos básicos de R a tomar en cuenta. Comencemos.
Paneles de R
De manera previa, resulta importante familiarizarse con el entorno gráfico de RStudio lo cual se puede observar en la siguiente imagen:
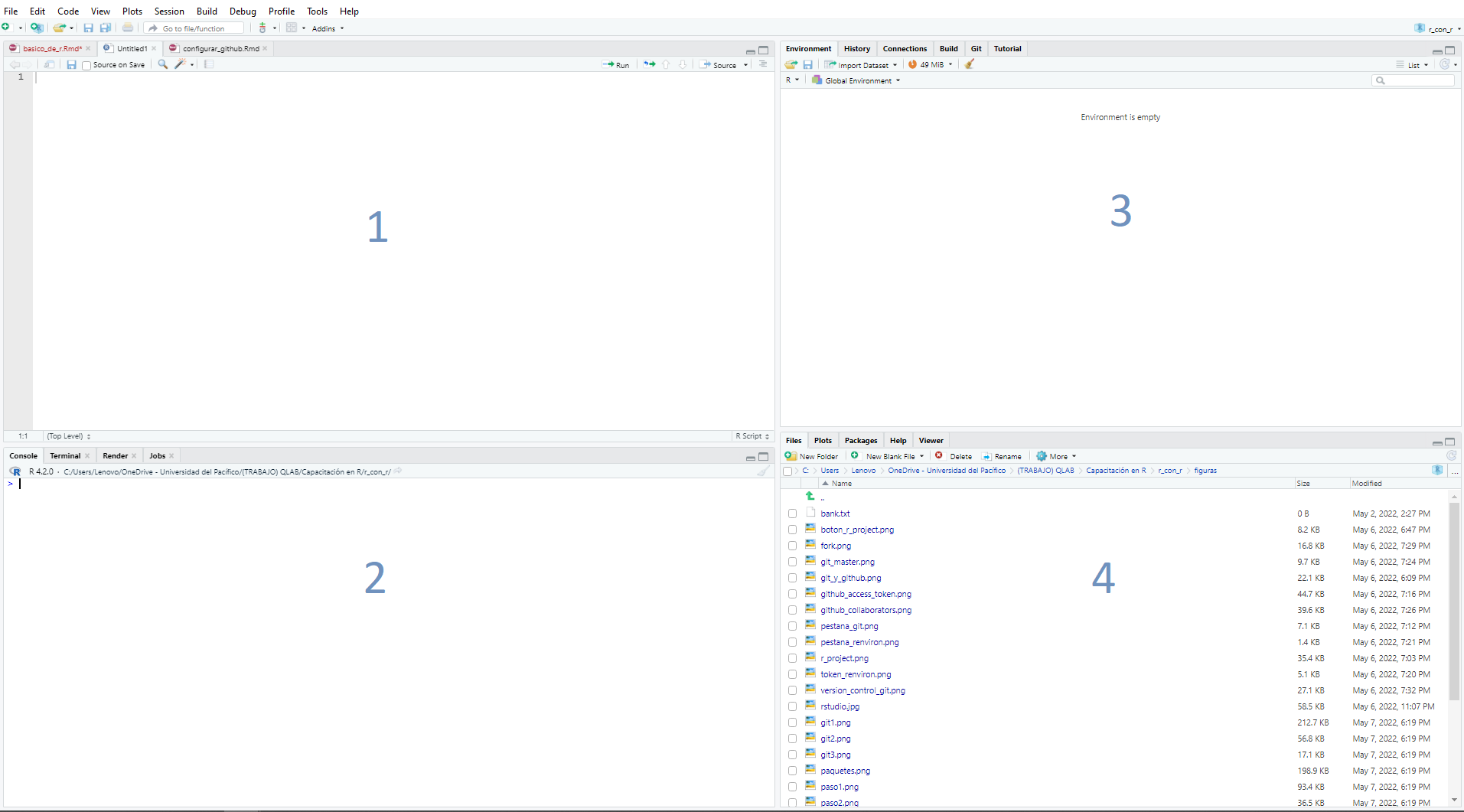
Sección 1
- Se encuentran los archivos o scripts (usualmente extensión
.Ry.Rmd) en los cuales podemos escribir código que queremos preservar o revisar más adelante. Si hacemos la analogía con Office Word, en el panel 1 estaría el documento en blanco a editar.
Sección 2
- Se encuentra la consola en la que podemos ingresar código de R directamente, pero que a diferencia del panel 1 no se guardará como parte de un documento. Asimismo, cualquier código que corramos en el panel 1 aparecerá en el panel 2 como una manera de llevar un registro durante la sesión. Ingresar código directamente en la consola es útil cuando queremos ejecutar porciones de código pequeñas o realizar operaciones matemáticas (R es como una calculadora…pro).
Sección 3
- Se encuentra el
Environmentdonde podemos visualizar los objetos que hemos creado en R. Más adelante profundizaremos en lo que significan los objetos, por ejemplo, si corres este código en la consolaa<-2+2te aparecerá en tuEnvironmentun vector numérico de valor 4, este vector se ha denominadoa.
Sección 4
- Se encuentran los archivos del usuario como si fuera la carpeta de “Mis Documentos” en Windows. De esta manera podemos acceder fácilmente a archivos de nuestra computadora y de nuestro directorio de trabajo.
Objetos
R en gran medida es un lenguaje orientado a objetos por lo que el resultado del código que ejecutamos puede ser encapsulado en un objeto para ser usado más adelante. Retomando el ejemplo anterior podemos ejecutar el siguiente código:
a<-2+2
a
[1] 4En el ejemplo anterior, he creado un objeto a y luego he
llamado ese objeto mencionando para que muestre lo que lleva adentro
(4). Ahora crearé el objeto b:
b<-5+1
b
[1] 6El objeto a y b son vectores numéricos por
lo que puedo realizar operaciones entre ellos. En primera instancia
puedo sumarlos entre ellos y/o con otros números:
a+b+6
[1] 16Tipos de objetos
A continuación veremos los tipos de objetos principales en R. Para
poder verificar el tipo de objeto nos apoyaremos de la función
class()
Vector numérico
Como vimos anteriormente, un vector numérico se compone de uno o más números lo que nos permite realizar operaciones aritméticas. Por ejemplo:
Cuando tenemos un vector con más de un número, las operaciones aritméticas que realizamos se aplican a cada uno de sus elementos:
#Cada elemento de d x 2
d*2
[1] 2 4Vector de caracteres
Un vector de caracteres almacena texto dentro de sus elementos. No permite que se realice operaciones aritméticas; no obstante, podríamos calcular la frecuencia con que se repite cada elemento. Por ejemplo:
palabras<-c("arroz", "jamón", "queso", 4,
"arroz", "jamón", "queso", 4,
"arroz", "jamón", "queso", 4,
"arroz", "jamón", "queso", 4)
class(palabras)
[1] "character"El objeto palabras es un vector “character” que engloba
texto únicamente, por lo que podemos contabilizar cuántos elementos
repetidos tiene:
table(palabras)
palabras
4 arroz jamón queso
4 4 4 4 Nótese que aunque he incluido un número a propósito (el 4) dentro de
un vector con texto, igual reconoce este número como un texto. En este
caso, se podría hacer la equivalencia: 4="4"="cuatro". Es
por ello que cuando realizamos una tabla de frecuencias contabiliza
cuántos 4 hay en vez de sumar los cuatro 4s.
Vector lógico
Un objeto lógico es un vector booleano dicotómico cuyos valores
pueden ser únicamente TRUE o FALSE. Por
ejemplo:
Los vectores lógicos son útiles cuando se trabaja con condiciones
lógicas del tipo if else. Por ejemplo:
#una abreviación para TRUE es T y para FALSE es F
aprueba_examen=T
#if(vector lógico){en caso TRUE}else{en caso FALSE}
if(aprueba_examen){"Felicitaciones por aprobar el examen"}else{"Más suerte la próxima"}
[1] "Felicitaciones por aprobar el examen"Dataframe
En la práctica de R, es más probable que trabajemos con dataframes antes que vectores. Un dataframe es un conjunto de vectores o variables que constituyen una matriz. Por ejemplo:
base<- data.frame(
persona=c("María Pía", "Santiago", "Pavel", "Mauricio"),
nota=c(15, 17, 20, 16),
aprueba=c(F,T,T,T)
)
base
persona nota aprueba
1 María Pía 15 FALSE
2 Santiago 17 TRUE
3 Pavel 20 TRUE
4 Mauricio 16 TRUEEn este dataframe de valores aleatorios podemos ver que tenemos los tres tipos de vectores = character, numérico, y lógico. Cabe mencionar que deben haber el mismo número de valores dentro de cada vector, es por ello que, cada vector cuenta con 4 valores.
Asimismo, un dataframe nos permite generar variables a partir de los valores de otras variables presentes en el dataframe. Por ejemplo:
base$mensaje<-ifelse(base$aprueba,"Felicitaciones por pasar el examen","Más suerte la próxima")
base
persona nota aprueba mensaje
1 María Pía 15 FALSE Más suerte la próxima
2 Santiago 17 TRUE Felicitaciones por pasar el examen
3 Pavel 20 TRUE Felicitaciones por pasar el examen
4 Mauricio 16 TRUE Felicitaciones por pasar el examenEstilos de programación en R
Estilo tradicional

En el estilo tradicional de programación en R, se aplican las funciones una dentro de otra como si fuera una “muñeca rusa”. Por ejemplo, si quisiera tener una tabla de porcentajes de un vector:
palabras<-c("arroz", "jamón", "queso", 4,
"arroz", "jamón", "queso", 4,
"arroz", "jamón", "queso", 4,
"arroz", "jamón", "queso", 4)
prop.table(table(palabras))*100
palabras
4 arroz jamón queso
25 25 25 25 En el ejemplo anterior, vemos que primero ejecutamos la función
table, luego prop.table que convierte los
resultados en porcentajes decimales, lo que luego multiplicamos por
100.
Estilo moderno

A diferencia del estilo tradicional de programar en R, actualmente
existe una tendencia a utilizar el pipe operator introducido en
el paquete {magrittr} que tiene este aspecto
%>%. La pipeta nos permite conectar funciones de manera
consecutiva antes que una dentro de otra. Por ejemplo, si quisieramos
replicar la tabla de porcentajes anterior en estilo moderno sería de la
siguiente manera:
# Para utilizar el operador pipe hay que desplegar el paquete dplyr
pacman::p_load(dplyr)
palabras %>%
table() %>%
prop.table() * 100
.
4 arroz jamón queso
25 25 25 25 Una manera de entender el flujo de trabajo de la pipeta es imaginar que le estamos diciendo al R: haz esto y luego esto, es decir ejecuta esta función u objeto y luego esta función sobre el mismo objeto creado.
Un atajo para introducir pipetas desde el teclado es apretando al
mismo tiempo: ctrl + shift +
m.
Preparación de data
Una vez aprendido acerca de dataframes y pipetas podemos
introducir las buenas prácticas al momento de trabajar con bases de
datos.
Es muy común recibir data en distintos formatos, muchos en los cuales nos cuesta trabajar y aplicar funciones. A partir de este problema surge el concepto Tidy data (data ordenada) que refiere a tener un caso por fila y una variable por columna.

Este concepto se encuentra en la base de los paquetes pertenecientes
al {tidyverse} que brindan distintas herramientas de
manipulación de la data para poder llegar a esta estructura tidy
data.
De igual manera, existe el concepto de tidy names cuando nos referimos al nombre de las variables. Muchas veces recibimos bases de datos con nombres de variables en un formato poco óptimo, por ejemplo:
base1<-data.frame(
a=c("Juan", "Jesús", "John"),
b=c(15, 16, 17)
)
names(base1)<- c("Señor 1", "Edad cumplida")
base1
Señor 1 Edad cumplida
1 Juan 15
2 Jesús 16
3 John 17En este caso, los nombres de las variables cuentan con espacios, caracteres especiales, mayúsculas, entre otros; lo cual dificulta la manipulación de las variables. Por ejemplo, si quisiera multiplicar la edad cumplida por 2 tendría que hacerlo de la siguiente manera:
base1$`Edad cumplida`<-base1$`Edad cumplida` * 2
base1
Señor 1 Edad cumplida
1 Juan 30
2 Jesús 32
3 John 34Para salvarnos de este problema se encuentra la función
clean_names() dentro del paquete {janitor} el
cual estandariza las nombres a un formato en el que podemos manipular
las variables fácilmente y también un nombre que no generará problemas
al exportarlo a formatos de data como .sav (SPSS),
.dta (STATA), entre otros.
base1 %>%
janitor::clean_names()
senor_1 edad_cumplida
1 Juan 30
2 Jesús 32
3 John 34Manejar directorios de trabajo
Al momento de importar y exportar nuestra data, es importante tener en cuenta a qué carpeta se están cargando los archivos. A esta carpeta la llamamos directorio de trabajo o Working directory. Para saber cuál es nuestro directory de trabajo por default ejecutamos la siguiente función:
getwd()
# [1] "C:/Users/Lenovo/OneDrive - Universidad del Pacífico/(TRABAJO) QLAB/Capacitación en R/r_con_r"
Si queremos cambiar nuestro directorio de trabajo a uno específico realizamos la siguiente función:
Más recursos para aprender: